Framework of Adversarial Perturbations
Adversarial Perturbations Formalization
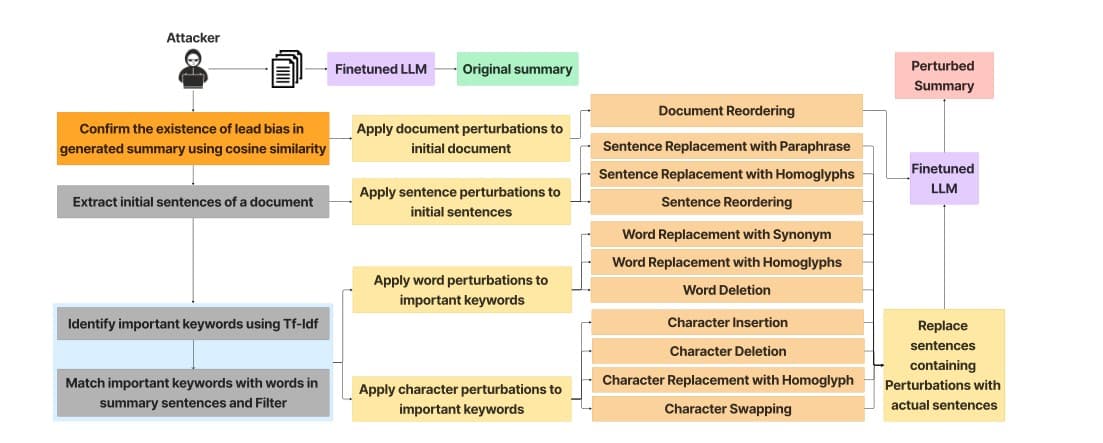
Initially, an attacker can finetune a pre-trained model on publicly available multi-document datasets and generate summaries. This step is crucial for identifying the model’s susceptibility to lead and document ordering biases. By analyzing these summaries and comparing them with sections of original documents using cosine similarity, attackers can confirm the presence of lead bias. Upon confirming these biases, attackers can extract initial sentences of the initial documents to apply perturbations.
Adversarial Perturbations Formalization
For a set of documents { D1, D2, ..., Dk }, where each Di consists of sentences {si1, si2, ..., sin }, we specifically target the lead sentences of the first document, Dlead = {s11, s12, ..., s1m }, with m being a small number, such as 2 or 3. This targeted approach stems from the hypothesis that alterations in the lead sentences of the first document can disproportionately influence the overall summary.
Identification of important tokens:
In character and word level, we employ TF-IDF to determine the important words within Dlead. Instead of applying adversarial perturbations to all the important words in the set, we match the words present in sentences of summary and filter them to apply perturbations. This set of selected words is denoted as Wimp. Our adversarial strategy involves applying a perturbation function p to Wimp. This function p(w) is designed to apply perturbations across characters and words in the set of Wimp, encompassing insertions, deletions, or homoglyph, synonym replacements while adhering to the constraint of minimal perturbation. At the sentence level, p(w) is designed to apply perturbations across Dlead, encompassing replacement with paraphrases and homoglyphs and re-ordering. At the document level p(w) is designed to apply perturbations across D1 by changing the document’s location from top to bottom. The application of p(w) to Dlead results in a perturbed version, D ′ lead.
Influence Functions for Data Poisoning
We have provide a novel attack strategy where attackers can employ influence functions to systematically target and modify training data, aiming to manipulate the behavior of text summarization models.
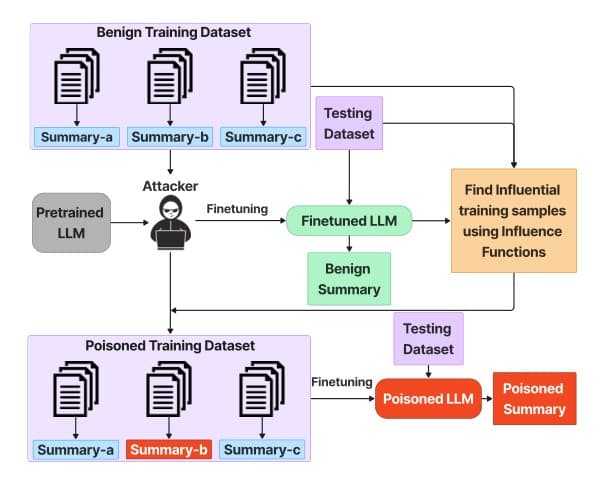
Illustration of poisoning attack using influence functions
Initual setup
Initially, an attacker can have access to a benign training dataset, a testing dataset, and a pre-trained LLM, which is publicly available. The pre-trained LLM can be finetuned using this benign 360 dataset and run on the test set to observe its original summarization behavior.
Utilization of Influence Functions
To poison a small sample of the training dataset, we utilize the concept of Influence Functions, which quantify the impact of training data points on the model’s predictions.
Generation of poisoned data
For each identified influential sample, we apply the dirty label attack and alter the summaries by creating a contrastive version or toxic version.
Model retraining
The model can then be finetuned by an attacker on the poisoned dataset, updating its parameters to adapt to the characteristics embedded within the poisoned dataset.
Datasets
- Multi-News dataset: This dataset consists of 44,972 training document 401 clusters, which includes news articles and human written summaries of these articles from the site newser.com.
- Multi-XScience dataset: a large-scale multi-document summarization dataset created from scientific articles. Multi-XScience introduces a challenging multi-document summarization task: writing the related-work section of a paper based on its abstract and the articles it references.